Bilibili
Bilibili Data Project I: Data Acquisition
The data analysis and visualization post is coming soon.
Introduction
I am analyzing the video meta data of bilibili.com, which is one of the largest video hosting platforms in China. It is estimated to have several tens of millions of videos.
There are two type of data that would be very useful. One of the is a snapshot of the current meta data of videos. The other one is time evolution of them.
Summary
For now I have obtained all the video meta data of the whole website. I also keep the monitoring program working on a remote server so that I obtain the time series data without disturbance.
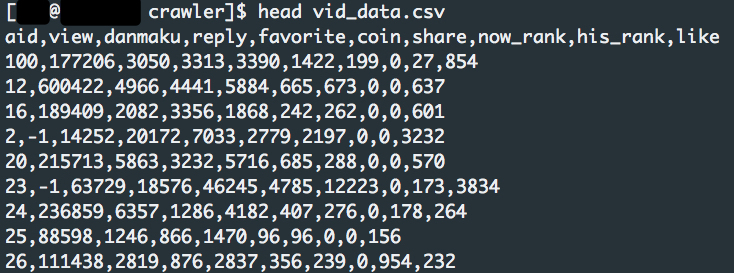
Data file off all the videos. This shows the first few lines of the csv data file. I choose csv file because the data is only on the scale of several GB.
I have built a dashboard to stream data from my server and visualize the data.
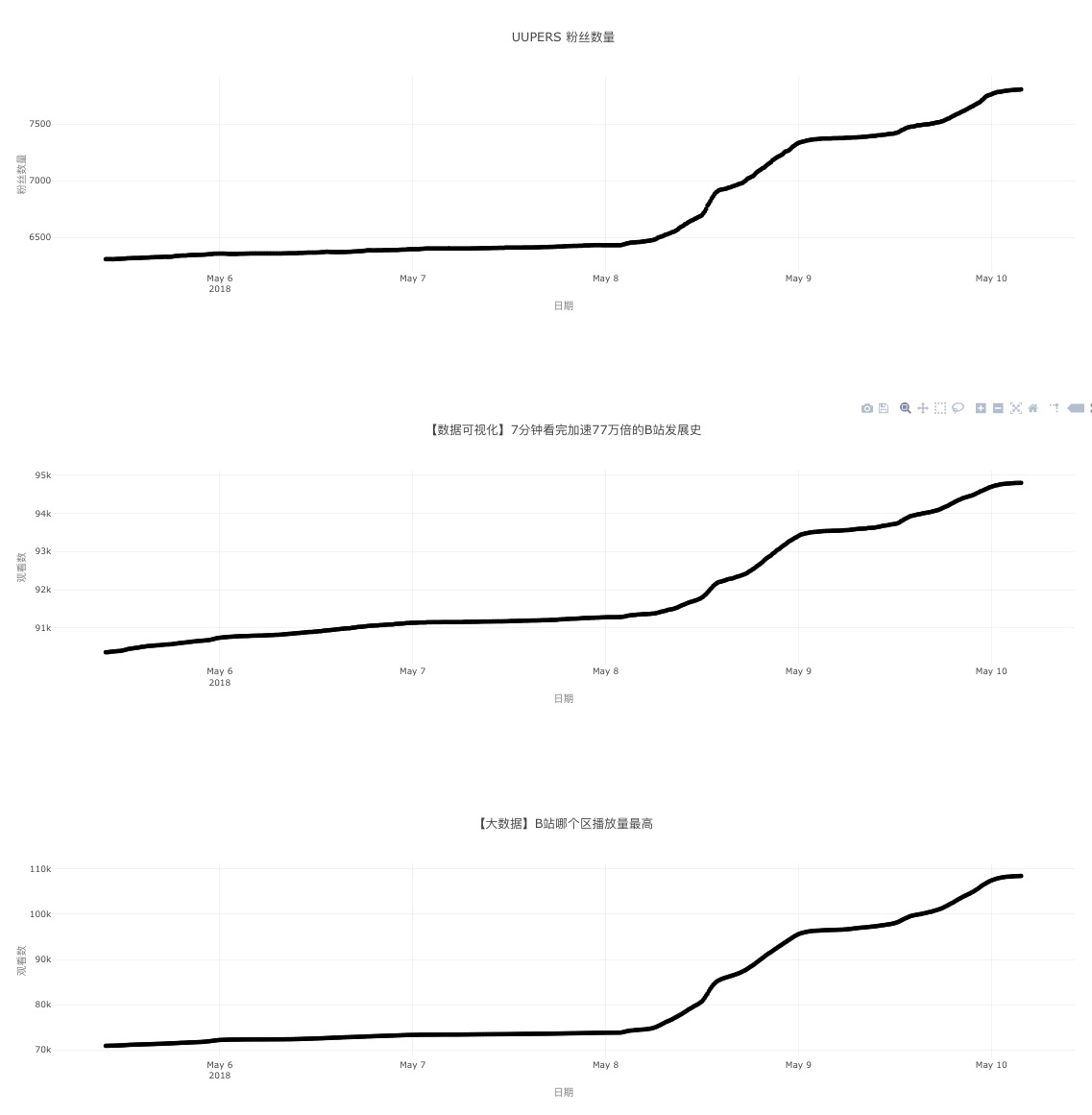
A dashboard for monitoring videos and users. The top panel is the number of fans vs time. The lower panels are the number of views of each video vs time.
Tasks Defined
- Grab video meta data from bilibili.com.
- Scrape a snapshot of all videos.
- Concentrate on some videos and monitor through time.
- Analyze the videos
- Analyze video meta data in general.
- Explore possible time evolution.
- Present the results.
Methods
Data Acquisition for All Videos (Code)
I choose to use Python as my tech stack. A list of modules and packages are listed bellow.
- requests
- json
- multiprocessing
The idea of this crawler is to request from API of bilibili.com and parse the data into data files. Following the lead, my code is arranged as follows.
# request data from the remote
requests.get( ' link to api ' )
# parse return of the remote
parse( ... )
# write data to file
VidDumpBatch( ... )Simple as it seems to write a working script, it takes some effort to optimize it. I have encountered several problems and solved them all.
requestsreturns errors. I implemented error handling and retry if connection failure. Retry function is set to increase time delay for each try.requestsreaches some limit and returns error of ‘max retries exceeded with url …’. The reason turns to berequestsdoesn’t close connections automatically. Naturally, the solution is to close the connections by hand.- The code efficiency is low.
- I had to remove most of the for loops and replace them with list comprehensions.
- I examined the cProfile using
snakevizand found that the most time consuming part is the url request, which is kind of trivial. So I utilizedmultiprocessingto create multiple processes of the requests. - Benchmarks were done to ensure efficiency.
Monitoring the Time Evolution of Videos ( Code )
The time series data is easier to obtain since it doesn’t require a large scale scraping.
The design of the framework is a complete separation of the front-end and back-end.
I have written the front-end first using Plotly.js and Vue.js, which can be accessed here. I have got nothing to say about it since it’s easy.
The back-end is written using Python, which can be accessed from here. I wrote a package named bilidash to provide all the functions and classes. I have
monitor-av.pymonitors the videos and export data as time series.record-front-page.pyscrapes and parses the front page and exports the video ids on front page.track-uupers.pytrackes some given users. Here I am interested in the user iduupers.uupers-vid-params.pytracks the videos of the useruupers. The trick of the whole project is to manage scheduled python jobs correctly, for which I used the standard library modulesched.
Future Work
As far as IO is concerned, the efficiency can be optimized by using binary data dumping, such as netcdf/hdf5.